知识
[大模型]离线更新本地ollama模型,拷贝ollama模型到离线电脑中安装使用deepseekR1模型更新增量更新update models
[大模型]使用chatbox和open-webui同时调用ollama管理器cs模式和bs模式同时使用,调用ollama:11434端口连接被对方重设关联deepseek
[大模型]ollama工具升级docker中升级ollama下载速度很慢的解决方案
[大模型]ollama容器离线升级ollama手动升级0.6.8
[大模型]Ollama pull拉取大模型时速度很慢slow download model file
[大模型]llama.cpp容器运行的方法docker run
[大模型]llama.cpp运行大模型容器的方案不能调用GPU的问题
本站点使用 MrDoc 构建
-
+
[大模型]llama.cpp容器运行的方法docker run
# 说明 为了解决ollama运行模型时,越来越慢的问题。ollama居然在调用qwen3.6时居然回答时间超过一分钟,硬件GPU为A100*4,很不正常!所以决定改用llama.cpp进行调用模型。 # 解决方案 ## 1、下载llama.cpp镜像 查询镜像网站: [https://docker.aityp.com/](https://docker.aityp.com/) ```bash docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/ggerganov/llama.cpp:server-cuda-b4646 docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/ggerganov/llama.cpp:server-cuda-b4646 ghcr.io/ggerganov/llama.cpp:server-cuda-b4646 ``` ==该网站对镜像启动的入口都由明确的说明:== 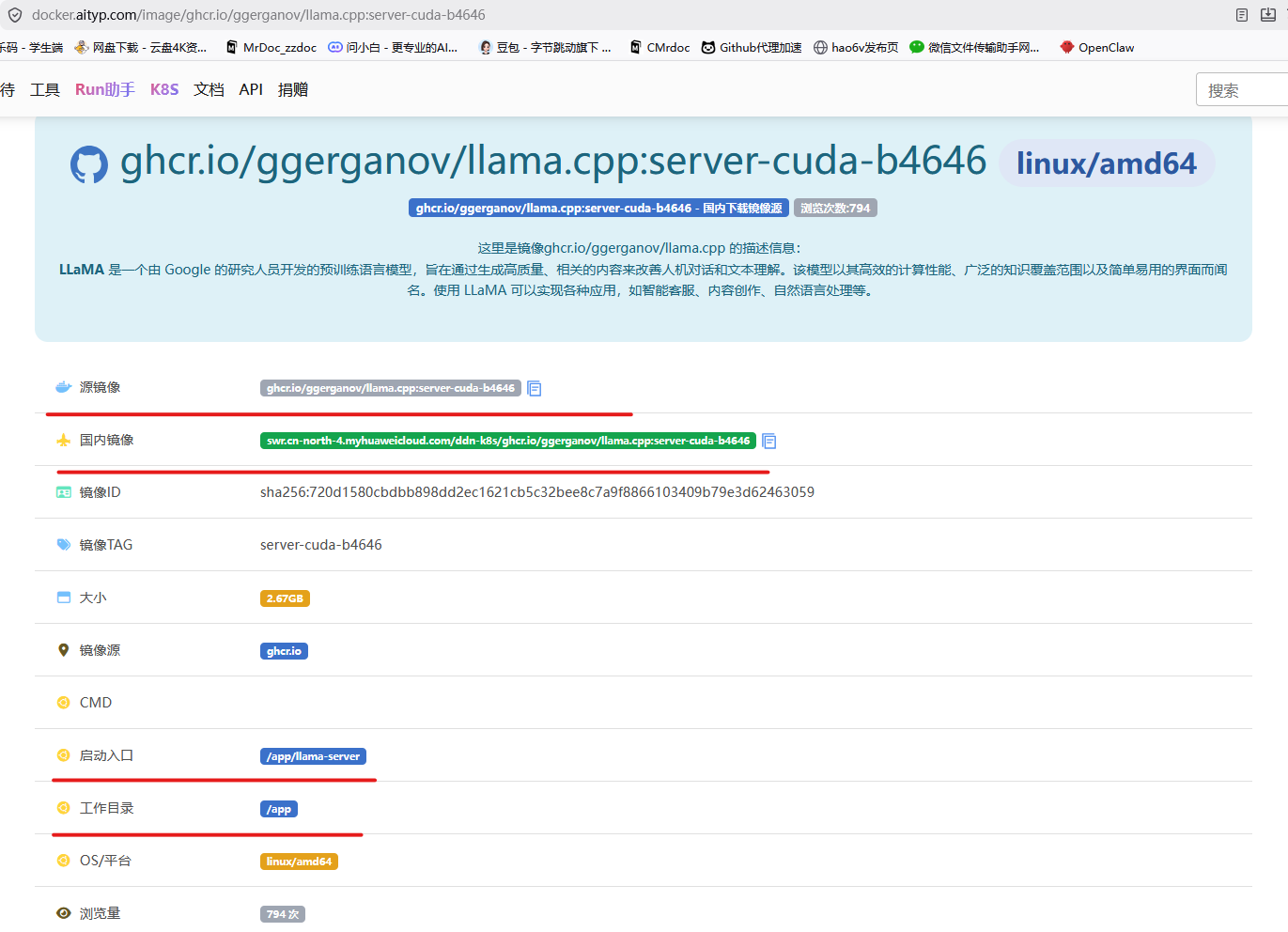 ## 2、下载模型 [https://hf-mirror.com](https://hf-mirror.com) [https://modelscope.cn/models](https://modelscope.cn/models) [https://ai.gitcode.com/models?isLogin=9](https://ai.gitcode.com/models?isLogin=9) llama.cpp对gguf模型支持,但是下载时,gguf的模型并不友好,很多模型都是.safetensors模型文件,需要进行转换才能使用。 有部分的模型,是第三方用户转的gguf文件,并非官方提供。 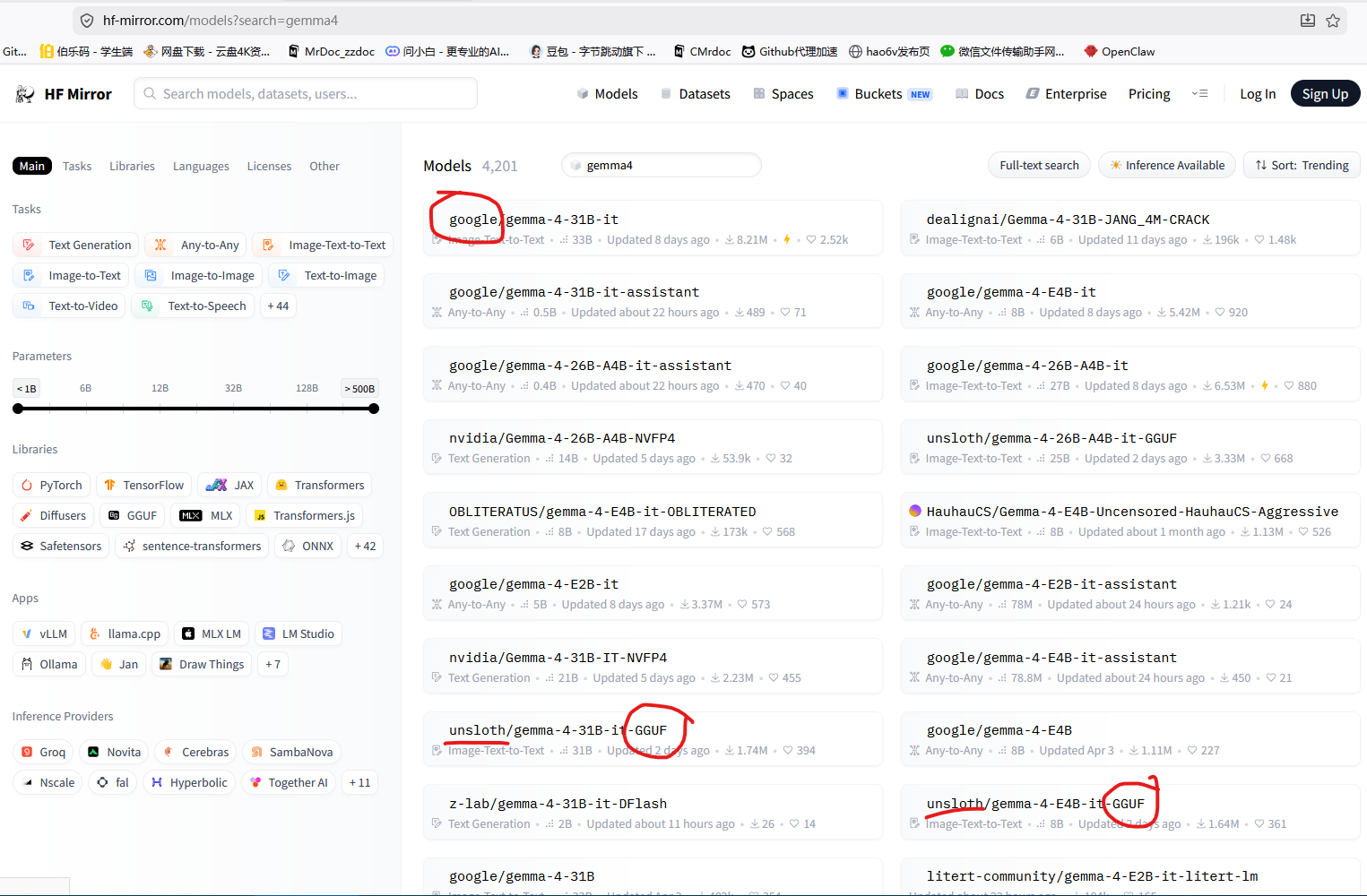 ==最好是,不下载大模型文件,仅下载小文件,大文件手动通过其他工具下载,可以断点续传== 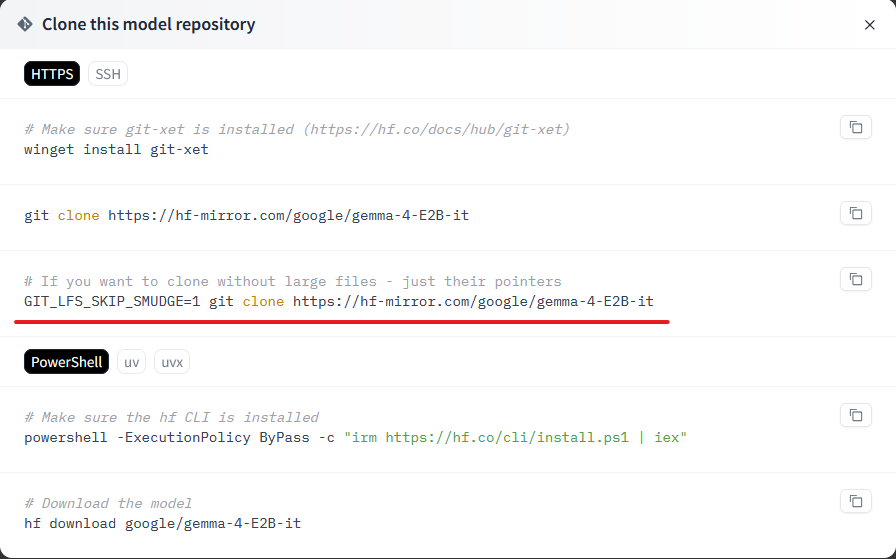 ```bash,不下载大文件 set GIT_LFS_SKIP_SMUDGE=1 && git clone https://hf-mirror.com/google/gemma-4-E2B-it ``` ```bash,下载大文件(不建议) git clone https://hf-mirror.com/google/gemma-4-E2B-it ``` 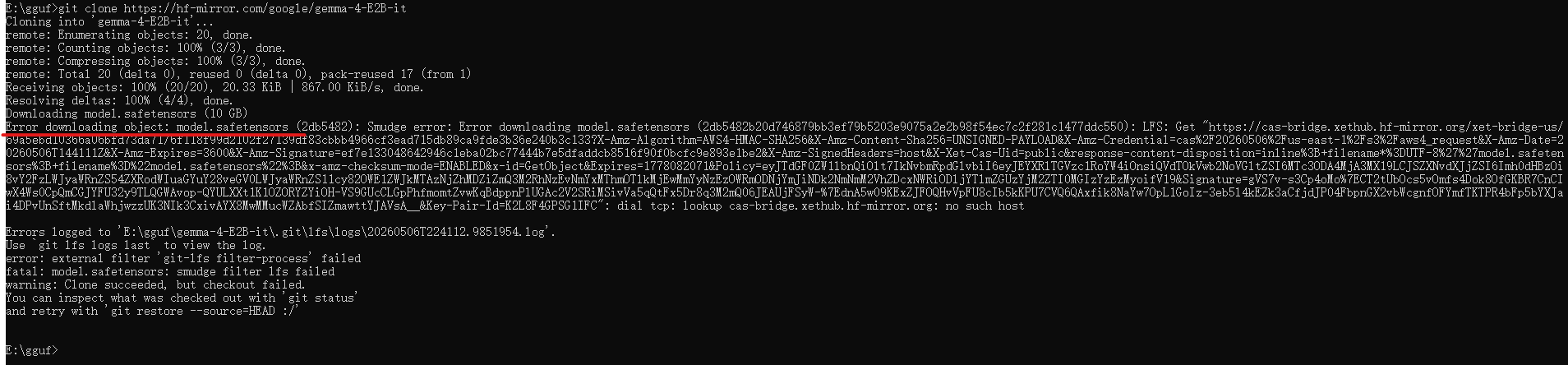 ==执行完不下载大文件后,再进入模型文件,选择需要下载的量化模型下载即可,最好使用gopeed,可以断点续传,并且速度快。== ## 3、safetensors转gguf文件 ```bash https://github.com/ggml-org/llama.cpp.git cd llama.cpp pip install -r requirements.txt python convert_hf_to_gguf.py E:\gguf\gemma-4-E2B-it --outfile E:\gguf\gemma-4-E2B-it-f16.gguf --outtype f16 ``` f16:不量化,质量最高,体积≈原大 q8_0:8 位,精度好,显存中等 q4_K_M:4 位,推荐日常用 q2_K:2 位,极限压缩,精度掉得多 ```bash,量化模型 build\Release\llama-quantize.exe ^ E:\gguf\gemma-4-E2B-it-f16.gguf ^ D:\models\gemma-1.1-4b-it-q4_k_m.gguf ^ Q4_K_M ``` 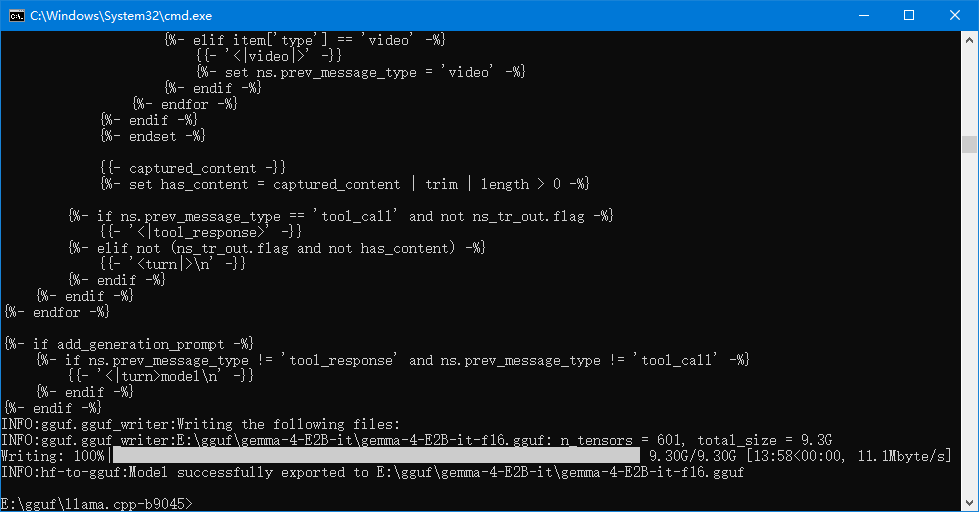 ## 4、运行模型 ```bash测试 docker run --rm -it \ -p 8080:8080 \ -v $(pwd):/models:ro \ ghcr.io/ggerganov/llama.cpp:light \ /app/llama-server \ --model /models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf \ --host 0.0.0.0 \ --port 8080 ``` ==注意:== ghcr.io/ggerganov/llama.cpp:light 该行之前的为docker命令参数 之后的命令为该容器服务运行命令
虚拟世界
2026年5月15日 20:19
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码